This is a tutorial-style article. I wrote it in June/July 2022, but found time to clean up and make a blog post only in September 2022.
This tutorial is relevant to software engineers and data scientists who work with Apache Beam on top of Apache Flink.
Our goal is to set up a local Beam and Flink environment that can run cross-language Beam pipelines.
Specifically, in this tutorial, I will discuss how to set up your laptop to run a Beam pipeline that:
- uses Kafka for source and sink
- runs on a local Flink cluster
- uses the Beam PortableRunner (not DirectRunner), which is required for Kafka I/O
I wrote my Beam pipelines on a Mac in Python, but I’ve also run pure-Java pipelines and it works nicely for those as well.
In this tutorial, we will run programs directly on the laptop, without a container layer, as much as possible.
Why have a local Beam-Flink environment?
Here are a few reasons why it is worth having a local Beam-Flink setup:
- When you are new to the system, a local setup helps understand the components and how they interact
- When developing pipelines, having a local environment makes pipeline development faster
- A local setup can help with reproducing production issues, investigating them and verifying fixes
In other words, after this tutorial, you can use your local environment:
- to understand Beam components through exploration and experimentation
- to quickly and iteratively develop pipelines on your laptop
- to reproduce, investigate and verify fixes for a production issue
I have included some sample explorations at the end of this tutorial.
Let’s get started with a big-picture overview.
System Architecture
The following diagram shows the steps involved in running a cross-language Beam pipeline on Flink using portable runner.
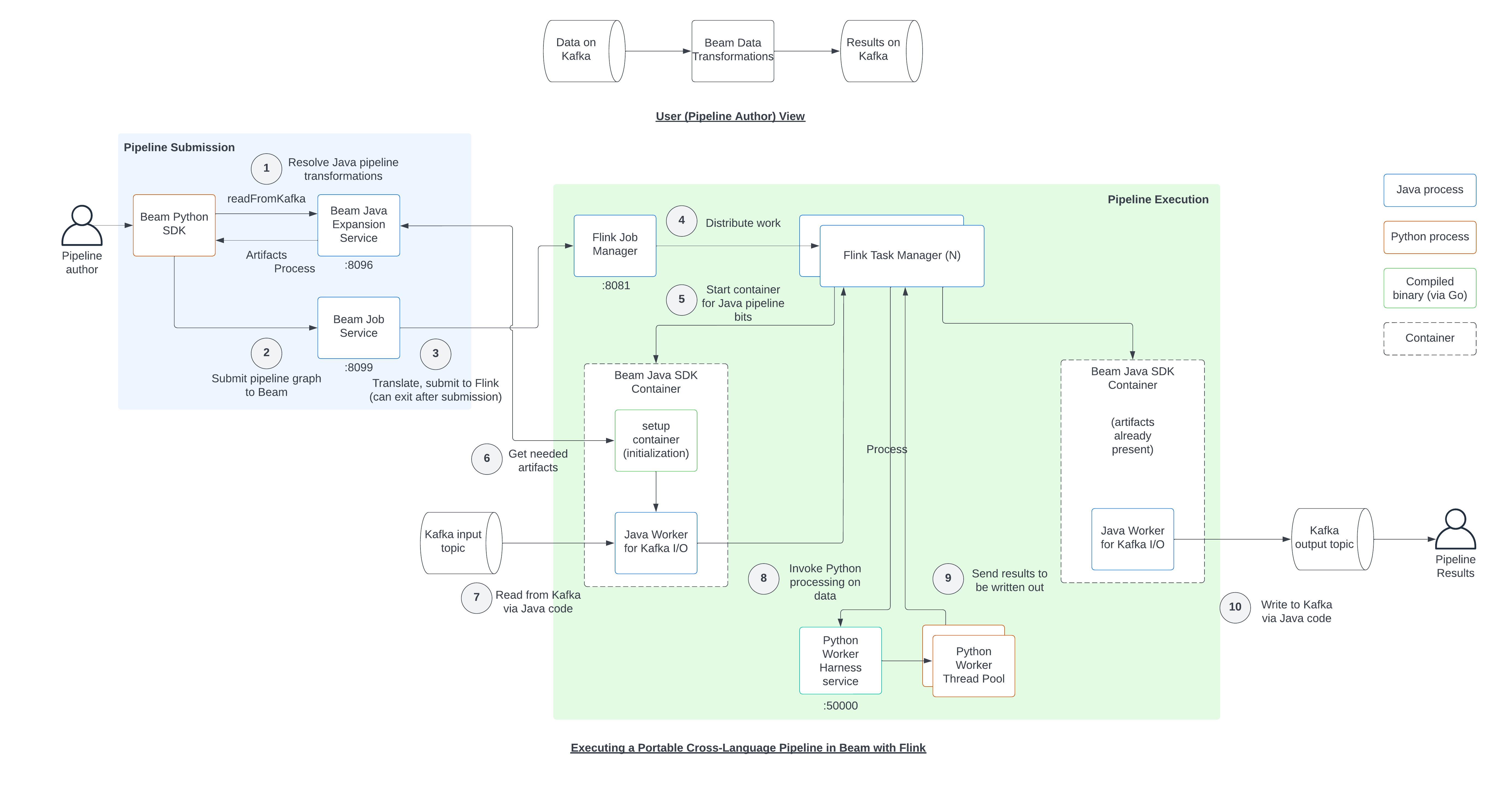
You can use the diagram as a reference as you work through the tutorial.
Our End-Goal State
We will run all but one component as programs running directly on the laptop.
At the end of the tutorial, the following software will be running on your laptop:
For Beam pipeline I/O:
- ZooKeeper and Kafka cluster
For Beam pipeline submission:
- Beam Job Server program
- Beam Expansion Service program
For Beam pipeline run-time:
- Flink cluster
- Python worker pool program
- Java worker harness program containers (started by Beam via Flink, not us – listing here only for completeness)
We provide additional context for each component as we go through this tutorial.
After we get these components running, we will write a simple pipeline to echo messages from Kafka.
Kick-Off
First, let us create a directory to work on:
$ mkdir -p ~/local_beam
$ cd ~/local_beam
Install Java SDK, if you don’t have one already:
$ brew install --cask adoptopenjdk8
We will use multiple terminal tabs to monitor the software as they run.
Terminal Tab 1: Kafka
Kafka is our data source and sink.
Install and start Kafka:
$ brew install kafka
$ zkServer start
ZooKeeper JMX enabled by default
Using config: /usr/local/etc/zookeeper/zoo.cfg
Starting zookeeper ... STARTED
$ /usr/local/opt/kafka/bin/kafka-server-start /usr/local/etc/kafka/server.properties
...
[2022-03-12 12:46:38,512] INFO Kafka version: 3.1.0 (org.apache.kafka.common.utils.AppInfoParser)
[2022-03-12 12:46:38,512] INFO Kafka commitId: 37edeed0777bacb3 (org.apache.kafka.common.utils.AppInfoParser)
[2022-03-12 12:46:38,512] INFO Kafka startTimeMs: 1647117998508 (org.apache.kafka.common.utils.AppInfoParser)
[2022-03-12 12:46:38,513] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
...
Create relevant topics on Kafka for our example pipeline:
$ /usr/local/opt/kafka/bin/kafka-topics --create --topic echo-input --bootstrap-server localhost:9092
Created topic echo-input.
$ /usr/local/opt/kafka/bin/kafka-topics --create --topic echo-output --bootstrap-server localhost:9092
Created topic echo-output.
Terminal Tab 2: Flink
Flink is our distributed computation system.
Install and start Flink:
$ curl -O -J https://www.apache.org/dyn/closer.lua/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.11.tgz
$ tar -zxf flink-1.14.4-bin-scala_2.11.tgz
$ ln -s flink-1.14.4 flink
$ ./flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host (yourhostname).
Starting taskexecutor daemon on host (yourhostname).
On your browser, go to localhost:8081 to monitor the Flink UI.
There should be one TaskManager (worker) by default, which is as good as running serially. This is OK and expected.
Terminal Tab 3: Beam Job Server
Beam provides a program model and run-time components to write and run distributed data pipelines.
Download Beam job server jar. We also need a few other jars for Kafka I/O.
$ wget https://repo1.maven.org/maven2/org/apache/beam/beam-runners-flink-1.14-job-server/2.38.0/beam-runners-flink-1.14-job-server-2.38.0.jar
$ wget https://repo1.maven.org/maven2/org/apache/beam/beam-sdks-java-extensions-schemaio-expansion-service/2.38.0/beam-sdks-java-extensions-schemaio-expansion-service-2.38.0.jar
$ wget https://repo1.maven.org/maven2/org/apache/beam/beam-sdks-java-io-kafka/2.38.0/beam-sdks-java-io-kafka-2.38.0.jar
$ wget https://repo1.maven.org/maven2/org/apache/beam/beam-sdks-java-io-expansion-service/2.38.0/beam-sdks-java-io-expansion-service-2.38.0.jar
We can now start the Job Server:
$ java -cp beam-runners-flink-1.14-job-server-2.38.0.jar:beam-sdks-java-extensions-schemaio-expansion-service-2.38.0.jar:beam-sdks-java-io-kafka-2.38.0.jar:beam-sdks-java-io-expansion-service-2.38.0.jar org.apache.beam.runners.flink.FlinkJobServerDriver --flink-master=localhost --job-host=0.0.0.0
May 24, 2022 1:15:45 PM software.amazon.awssdk.utils.Logger warn
WARNING: Ignoring profile 'bigstore' on line 20 because it did not start with 'profile ' and it was not 'default'.
May 24, 2022 1:15:45 PM org.apache.beam.runners.jobsubmission.JobServerDriver createArtifactStagingService
INFO: ArtifactStagingService started on 0.0.0.0:8098
May 24, 2022 1:15:45 PM org.apache.beam.runners.jobsubmission.JobServerDriver createExpansionService
INFO: Java ExpansionService started on 0.0.0.0:8097
May 24, 2022 1:15:45 PM org.apache.beam.runners.jobsubmission.JobServerDriver createJobServer
INFO: JobService started on 0.0.0.0:8099
May 24, 2022 1:15:45 PM org.apache.beam.runners.jobsubmission.JobServerDriver run
INFO: Job server now running, terminate with Ctrl+C
...
Terminal Tab 4: Beam Java Expansion Service
Beam allows users to create a pipeline written in multiple languages.
In our case, Kafka I/O driver is written in Java.
Beam provides a service that can retrieve and temporarily store (“stage”) artifacts needed for transforms written in Java.
During submission, this service also provides translation to allow a Python pipeline to use a Java pipeline component. It’s a preprocessing step that happens before Beam Job Server actually sees your pipeline.
We already downloaded the relevant jar file, because Beam Job Server depends on it. We can simply start it now.
$ java -cp beam-runners-flink-1.13-job-server-2.38.0.jar:beam-sdks-java-extensions-schemaio-expansion-service-2.38.0.jar:beam-sdks-java-io-kafka-2.38.0.jar:beam-sdks-java-io-expansion-service-2.38.0.jar \
org.apache.beam.sdk.expansion.service.ExpansionService 8096 \
--defaultEnvironmentType=DOCKER \
--defaultEnvironmentConfig=apache/beam_java11_sdk:2.38.0 \
--experiments=use_deprecated_read
Starting expansion service at localhost:8096
Jun 05, 2022 3:03:36 PM org.apache.beam.sdk.expansion.service.ExpansionService loadRegisteredTransforms
INFO: Registering external transforms: [beam:transform:org.apache.beam:schemaio_jdbc_read:v1, beam:transform:org.apache.beam:schemaio_jdbc_write:v1, beam:transform:org.apache.beam:schemaio_avro_read:v1, beam:transform:org.apache.beam:schemaio_avro_write:v1, beam:external:java:generate_sequence:v1, beam:transform:org.apache.beam:kafka_read_with_metadata:v1, beam:transform:org.apache.beam:kafka_read_without_metadata:v1, beam:transform:org.apache.beam:kafka_write:v1]
beam:transform:org.apache.beam:schemaio_jdbc_read:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@7c137fd5
beam:transform:org.apache.beam:schemaio_jdbc_write:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@183ec003
beam:transform:org.apache.beam:schemaio_avro_read:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@7d9d0818
beam:transform:org.apache.beam:schemaio_avro_write:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@221a3fa4
beam:external:java:generate_sequence:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@451001e5
beam:transform:org.apache.beam:kafka_read_with_metadata:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@2b40ff9c
beam:transform:org.apache.beam:kafka_read_without_metadata:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@3e08ff24
beam:transform:org.apache.beam:kafka_write:v1: org.apache.beam.sdk.expansion.service.ExpansionService$ExternalTransformRegistrarLoader$1@4d1c005e
...
In case you are wondering, the command-line arguments specify the following behavior for pipelines:
- use Docker as the container environment in which to start worker harness code
- which container environment to use for Kafka I/O code (Beam Java11 SDK)
- use an older read function for Kafka
With this, Beam, via Flink, will start up Java workers for Kafka I/O.
The workers run on a Docker container. This is the container image we specified in the command-line. Beam will download the container image if not present.
Terminal Tab 5: Python Worker Harness
Usually, pipelines invoke functions that run in parallel on small bundles of data.
Beam comes with an SDK to allow Python programs to invoke Beam transformations via Python functions.
We will run the Python worker directly, not within a Docker container. Note: this is not an option for Java harness, i.e. it has to run within a container.
Install Python SDK for Beam:
$ pip install apache-beam==2.38.0
Beam’s Python worker harness starts up a Python environment to run any Python transformations in our pipeline.
Beam provides a “boot” program to start the worker thread pool.
Beam hard-codes this to be in a fixed location. Let us copy it there and run it.
$ docker pull apache/beam_python3.8_sdk
$ docker run --name beam-python-sdk -it --entrypoint bash apache/beam_python3.8_sdk
# in a separate temporary tab, copy the boot file
$ sudo mkdir -p /opt/apache/beam/boot
$ sudo docker cp beam-python-sdk:/opt/apache/beam/boot /opt/apache/beam/boot
# back in the original tab, press Ctrl-D to exit the container, then start the worker pool:
$ /opt/apache/beam/boot -worker_pool
2022/06/06 12:49:15 Starting worker pool 51784: python -m apache_beam.runners.worker.worker_pool_main --service_port=50000 --container_executable=/opt/apache/beam/boot
INFO:__main__:Listening for workers at localhost:50000
INFO:__main__:Started worker pool servicer at port: localhost:50000 with executable: /opt/apache/beam/boot
...
NOTE 1: You should start the worker pool from the same directory as your Python pipeline directory. Otherwise, it will not find your code at run-time.
NOTE 2: If you make changes to worker functions, you should stop and re-run the above boot program.
This completes our setup. At this point, we are ready to run the pipeline.
Running the Pipeline
Let us write an “echo” Beam pipeline in Python that copies data from a Kafka topic A to Kafka topic B:
# pipeline.py
# Sample Beam Program that uses Kafka for I/O.
# Set up to run locally for now. See steps below for preparing your runtime environment.
import apache_beam as beam
from apache_beam.io import kafka
from apache_beam.options.pipeline_options import PipelineOptions, SetupOptions
import typing
# Our distributed processing functions go here
import worker
job_server = "localhost"
expansion_service = "localhost:8096"
# Set up this host to point to 127.0.0.1 in /etc/hosts
bootstrap_servers = "host.docker.internal:9092"
kafka_consumer_group_id = "kafka_echo"
input_topic = "echo-input"
output_topic = "echo-output"
def init_pipeline(job_server=job_server):
pipeline_opts = {
# MUST BE PortableRunner
"runner": "PortableRunner",
"job_name": "kafka_echo_demo",
"job_endpoint": f"{job_server}:8099",
"artifact_endpoint": f"{job_server}:8098",
"environment_type": "EXTERNAL",
"environment_config": "localhost:50000",
"streaming": True,
"parallelism": 2,
"experiments": ["use_deprecated_read"],
"checkpointing_interval": "60000",
}
pipeline_options = PipelineOptions([], **pipeline_opts)
# Required, else it will complain that when importing worker functions
pipeline_options.view_as(SetupOptions).save_main_session = True
pipeline = beam.Pipeline(options=pipeline_options)
return pipeline
def run_pipeline(pipeline):
_ = (
pipeline
| "ReadMessages" >> kafka.ReadFromKafka(consumer_config={
"bootstrap.servers": bootstrap_servers,
"group.id": kafka_consumer_group_id,
},
topics=[input_topic],
expansion_service=expansion_service,
)
| beam.Map(lambda r: worker.kafka_record_processor(r)).with_output_types(typing.Tuple[bytes, bytes])
| "WriteToKafka" >> kafka.WriteToKafka(producer_config={"bootstrap.servers": bootstrap_servers},
topic=output_topic,
expansion_service=expansion_service,
))
pipeline.run().wait_until_finish()
if __name__ == '__main__':
p = init_pipeline()
run_pipeline(p)
Here is the Python code that runs in worker components.
# worker.py
#
# This file contains code required to run functions
# in worker nodes during Beam's distributed data processing
#
# It is also imported in the main pipeline
# However, any code needed during both building and at run-time
# should go to this file.
def kafka_record_processor(kafka_kv_rec):
"""dummy function that runs in the worker to echo a Kafka record"""
# Incoming Kafka records must have a key associated.
# Otherwise, Beam throws an exception with null keys.
assert isinstance(kafka_kv_rec, tuple)
print("Got kafka record value: ", str(kafka_kv_rec[1]))
rec_key = str(kafka_kv_rec[0])
rec_val = str(kafka_kv_rec[1])
# return record as tuple[key, value] in bytes for echoing
return bytes(rec_key, "utf-8"), bytes(rec_val, "utf-8")
You can copy these files into a directory and run the pipeline.
Again, remember to note these from the previous section:
- You should start the worker pool from the same directory as your Python pipeline directory. Otherwise, it will not find your code at run-time.
- If you make changes to worker functions, you should stop and re-run the above boot program.
We can submit and run the pipeline:
$ python pipeline.py submit --job_server=localhost
INFO:root:Default Python SDK image for environment is apache/beam_python3.8_sdk:2.38.0
INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
INFO:apache_beam.runners.portability.portable_runner:Job state changed to STARTING
INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
...
After a few seconds, the Flink UI should show a pipeline as “RUNNING”. If it does not, look under the Beam Job Server and Beam Expansion Service tabs for any errors.
We can send a message on the input topic and wait for it to show up on the output topic.
We will use the kcat program to send a message and wait for it to show on the output topic.
$ brew install kcat
$ echo '{ "value": {"message": "hello, world" }}' | kcat -b localhost:9092 -P -k "testMessage" -t echo-input
$ kcat -b localhost:9092 -C -t echo-output
{ "value": {"message": "hello again, world" }}
% Reached end of topic echo-output [0] at offset 2
The pipeline will continue to wait for messages. You have to explicitly cancel the Flink job to terminate it.
If there was a problem while running the pipeline, an exception will show on the Flink UI.
The following points are of note about the pipeline program.
NOTE 1: Our pipeline uses “external” worker harness for Python, this is why we started a Python worker-pool program.
This worker-pool executes any code we call via, say, beam.Map().
NOTE 2: We specified Kafka host as host.docker.internal. This is required for Kafka code running on a container
(started by Beam Java worker harness) to be able to talk to Kafka on our laptop.
NOTE 3: Any posted Kafka message must include a key as well. Beam threw errors with null keys.
Sample Exploration
Our setup allows us to explore how a pipeline is executed. We now outline a few instructive possibilities below.
Exploration 1: What is the role of expansion service?
Suppose we stop the expansion service. If we try to run the pipeline, it throws an error when getting Kafka transforms:
2022-03-12 19:55:01,908 INFO __main__ (echo_kafka.py:submit:91) Calling kafka read
Traceback (most recent call last):
File "echo_kafka.py", line 93, in submit
pipeline
...
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/pipeline.py", line 708, in apply
pvalueish_result = self.runner.apply(transform, pvalueish, self._options)
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/runners/runner.py", line 186, in apply
return m(transform, input, options)
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/runners/runner.py", line 216, in apply_PTransform
return transform.expand(input)
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/transforms/external.py", line 473, in expand
response = service.Expand(request)
...
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses"
>
We note that the exception has happened where we call kafka.ReadFromKafka(), i.e. not later, at pipeline.run().
It appears that when Beam sees this call, it immediately asks expansion service for the relevant artifacts. This is why ReadFromKafka() requires an expansion service address.
Exploration 2: Understanding the Beam job server
As another example, suppose we stop the Beam Job Server, but keep the expansion service running.
Now we see that the pipeline fails later, as a timeout when actually trying to run the pipeline:
Traceback (most recent call last):
...
File "echo_kafka.py", line 127, in submit
result = pipeline.run()
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/pipeline.py", line 573, in run
return self.runner.run_pipeline(self, self._options)
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/runners/portability/portable_runner.py", line 465, in run_pipeline
job_service_handle = self.create_job_service(options)
File "/Users/deepaknagaraj/.pyenv/versions/3.8.12/lib/python3.8/site-packages/apache_beam/runners/portability/portable_runner.py", line 341, in create_job_service
return self.create_job_service_handle(server.start(), options)
...
This means Beam submits a fully formed pipeline to Job Server for execution.
Note: Because there is no way to customize how Beam Job Server starts its expansion service, we start our own instead.
Exploration 3: How does Beam create and use containers?
As a final example, we can explore how Beam is starting up the Java SDK container and doing Kafka I/O:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
601102cf82e7 apache/beam_java11_sdk:2.35.0.dev "/opt/apache/beam/bo…" 14 seconds ago Up 14 seconds laughing_almeida
379c1deee7ed apache/beam_java11_sdk:2.35.0.dev "/opt/apache/beam/bo…" 14 seconds ago Up 14 seconds vibrant_engelbart
$ docker logs 601102cf82e7
...
2022/03/13 16:56:53 Initializing java harness: /opt/apache/beam/boot --id=1-1 --provision_endpoint=host.docker.internal:61831
2022/03/13 16:56:53 Downloaded: /tmp/1-1/staged/dnsns-UfOlGFOd_Ze6Duy7Z-Mvay_f1u7FYl7DtVG9GrTeG3Q.jar (sha256: 51f3a518539dfd97ba0eecbb67e32f6b2fdfd6eec5625ec3b551bd1ab4de1b74, size: 8282)
2022/03/13 16:56:53 Downloaded: /tmp/1-1/staged/jaccess-wGNFBDz-KwYU01meZaEWRmGsjOGUAA_6G5z2MNiQKXc.jar (sha256: c06345043cfe2b0614d3599e65a1164661ac8ce194000ffa1b9cf630d8902977, size: 44512)
2022/03/13 16:56:56 Downloaded: /tmp/1-1/staged/localedata-UD1o9dnAKwWFgznCIgA7pJYJvoMcen83cP06FMkOxZE.jar (sha256: 503d68f5d9c02b05858339c222003ba49609be831c7a7f3770fd3a14c90ec591, size: 1182622)
2022/03/13 16:56:57 Downloaded: /tmp/1-1/staged/nashorn-BLQxDoSLTIcEqwueE6e7HZYAt85l64clAhOVPDFuEmI.jar (sha256: 04b4310e848b4c8704ab0b9e13a7bb1d9600b7ce65eb87250213953c316e1262, size: 2033827)
2022/03/13 16:56:57 Downloaded: /tmp/1-1/staged/cldrdata-qdug83pFRRvlUhmPg3-2zn8oqD0qqqxUnswCFrVd90c.jar (sha256: a9dba0f37a45451be552198f837fb6ce7f28a83d2aaaac549ecc0216b55df747, size: 3861283)
2022/03/13 16:56:57 Executing: java -Xmx1456918937 -XX:+UseParallelGC -XX:+AlwaysActAsServerClassMachine -XX:-OmitStackTraceInFastThrow -cp /opt/apache/beam/jars/slf4j-api.jar:/opt/apache/beam/jars/slf4j-jdk14.jar:/opt/apache/beam/jars/beam-sdks-java-harness.jar:/opt/apache/beam/jars/beam-sdks-java-io-kafka.jar:/opt/apache/beam/jars/kafka-clients.jar:/opt/apache/beam/jars/beam-runners-flink-job-server.jar:/tmp/1-1/staged/cldrdata-qdug83pFRRvlUhmPg3-2zn8oqD0qqqxUnswCFrVd90c.jar:/tmp/1-1/staged/dnsns-UfOlGFOd_Ze6Duy7Z-Mvay_f1u7FYl7DtVG9GrTeG3Q.jar:/tmp/1-1/staged/jaccess-wGNFBDz-KwYU01meZaEWRmGsjOGUAA_6G5z2MNiQKXc.jar:/tmp/1-1/staged/localedata-UD1o9dnAKwWFgznCIgA7pJYJvoMcen83cP06FMkOxZE.jar:/tmp/1-1/staged/nashorn-BLQxDoSLTIcEqwueE6e7HZYAt85l64clAhOVPDFuEmI.jar org.apache.beam.fn.harness.FnHarness
...
We can see that the container downloaded files from the staging area, and then started up FnHarness for Kafka I/O.
These files are coming from the expansion service we started earlier. It is easy to verify this; if we stop the service after the pipeline starts, the pipeline fails because it won’t be able to retrieve the artifacts to start up the Java harness for Kafka I/O:
2022/03/13 18:57:23 Initializing java harness: /opt/apache/beam/boot --id=1-1 --provision_endpoint=host.docker.internal:50456
2022/03/13 18:57:33 Failed to retrieve staged files: failed to retrieve /tmp/1-1/staged in 3 attempts: failed to retrieve chunk for /tmp/1-1/staged/cldrdata-qdug83pFRRvlUhmPg3-2zn8oqD0qqqxUnswCFrVd90c.jar
Cleanup
After we are done, we can stop the programs:
<press Ctrl-c on Beam job server to stop the program>
<press Ctrl-c on Beam expansion service to stop the program>
<press Ctrl-c on Python worker pool to stop the program>
$ ~/local-beam/flink/bin/stop-cluster.sh
<press Ctrl-c on the Kafka tab, wait for it to finish>
$ zkServer stop
Conclusion
In this tutorial, we learned how to run a Beam pipeline that:
- is written in Python, and
- uses Kafka for input and output, and
- runs on Flink, and
- runs fully on developer system
We gave an overview of the necessary runtime components. Along the way, we also explained why these components were necessary.
We then wrote a simple Beam pipeline in Python.
You can continue to use this environment for local, iterative development.
You can also use it to reproduce, debug, and verify fix for a problem that occurred in production environment.