Machine learning teams today often want to process data in real-time. They also standardize on Python as a programming language. Apache Beam supports Python and gives a lot of hope, but my opinion is that this combination is practically too complex and unreliable to put in production.
This is an opinion piece. The audience is a technical lead or architect in a data or ML infrastructure team who is trying to decide technology stack for data processing pipelines in Python. I have nothing personal against the developers of Beam; I think it is a well-intentioned project that is not set up to succeed in execution.
About Beam
Beam is a programming framework and runtime developed by Google for data processing pipelines. Its goal is lofty: it aims to be a glue that supports multiple languages on the one end and multiple data processing systems (“runners”) on the other:
With an abstraction like Beam, a pipeline can be written once in a language familiar to the programmer and be ported to a new runner if needed, as long as Beam supports it. Beam also aims to support a pipeline with different steps of the pipeline written in different languages. Finally, Beam aims to unify streaming and batch pipelines from a programmatic perspective.
The Problem with Beam
The goal is so ambitious that Beam is destined to be a mess in reality. To begin with, they aim to support many languages and runners, creating fan-outs on either end of Beam. As if this is not enough work, they also want to support multiple languages within a single pipeline, something they call the “portability framework”. Architecturally, the portability framework is complex (more in a bit), relatively new and not well-supported, but it is the desired goal of the project.
To summarize, if you want to use Beam, you have to select from four degrees of freedom:
- Processing type (streaming or batch? or in Beam terminology, unbounded vs. bounded data?)
- Language (Java? Python? Go? etc.)
- Runner (Cloud Dataflow? Flink? Spark? etc.)
- Runtime architecture (Classic? Portability?)
This is a combinatorial explosion. With this level of sprawl1, two things can happen, practically speaking. First, extreme flexibility leads to fragmentation, quality and support issues, and ultimately loss of adoption and community. Second, network effects will apply and one or two combinations will take the lead, de facto, leaving the project with a small but strong core and a mess all around.
Indeed, Beam has a couple of paved paths: if you write your Beam pipeline in Java only, and run it on Google Cloud Dataflow or Apache Flink, you’re probably fine. Otherwise, the degree of support is highly variable. If you have a production pipeline in a non-standard combination and there is a problem, well, tough luck. Documentation is thin, in no small part because there are so many combinations to support. The user community is a fraction of the size of Spark community, with further fragmentation across various the various degrees of freedom I mentioned earlier.
I mentioned that the portability framework is complex. The runtime requires orchestration across many components, including a container environment, that makes it hard to understand component interactions and investigate and debug problems. Even setting up a local development environment is a challenge. Often, the boundaries are unclear between Python and Java, Beam and Flink, and components such as Job Server and Expansion Service. This makes it a challenge to narrow down a problem if there is a multitude of components written by separate vendors.
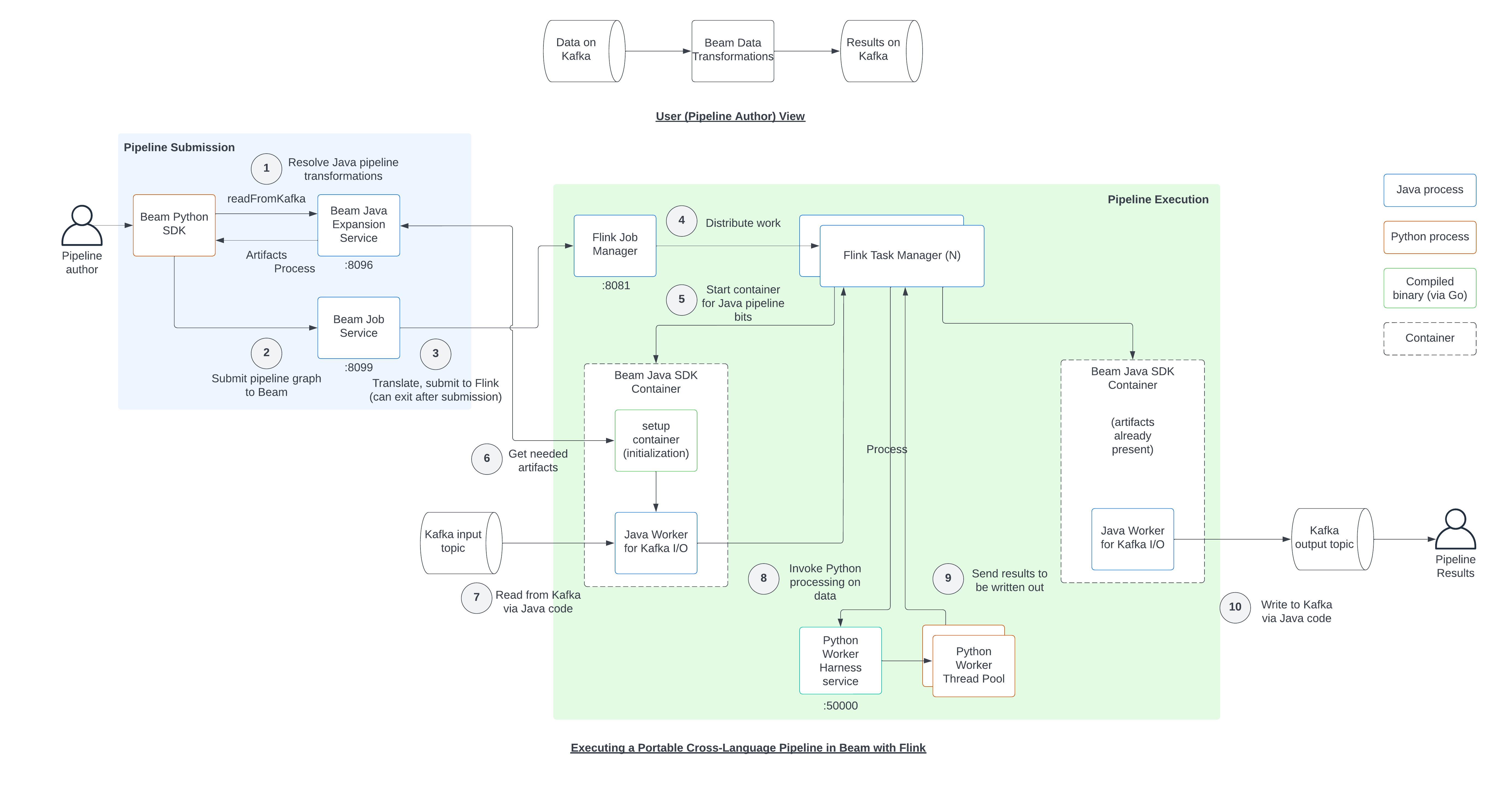
Sometimes there is no choice but to use the portability framework, even if the pipeline itself is in one language. For example, as of 2022, if you read or write Kafka in your pipeline, you’re forced to use the Java implementation of Beam for that step, and that in turn forces you into the portability framework along with all of its ramifications. It doesn’t matter that your data processing is in Python.
This implementation reality goes strongly against a data processing system requirements: it needs to be simple, reliable, stable, and efficient. Note that considerable complexity already exists because a pipeline interacts with disparate data, data sources, and data sinks, often continuously. The processing system cannot make this much worse.
Now suppose you do go with a safe Beam combination: Java and Flink. Even then, because you access Flink through Beam, not all features of Flink are available. For example, in 2022 we discovered that we were seeing checkpoint failures in Flink and they could be fixed by unaligned checkpoints, but this feature was not available on Beam.2 Also, what is the benefit of Beam, if Flink already provides a Java SDK to write pipelines?
Even if Beam had 100% compatibility with the underlying runners and worked flawlessly with supported languages, I still have a fundamental question. Is pipeline portability a problem large enough that we need something like Beam? In practice, data infrastructure is complicated and pipelines are only one part of the solution. If the processing constructs are sufficiently high-level functions or even SQL, it’s trivial to port. Yet, if we choose Beam, we are paying the cost of Beam complexity in the present, continuously, for a simple problem that might never materialize. Also, Beam allows us to decouple our pipeline logic from the underlying runners and languages, but we have now coupled our pipeline to Beam itself.
It is perhaps easier to defend the other Beam goal of unifying streaming and batch paradigms, but that convenience is somewhat lost in the muddle.
To Be(am) or Not
I have serious misgivings with using Beam in a production environment, unless it is one of the paved paths I mentioned above. Even there, with Flink for example, I would strongly ask myself whether the abstraction of Beam is giving any benefit that Flink itself does not.
In general, I would strongly look at how big a user community is before adopting open-source projects. Essentially, the argument for open-source software is one of eyeballs. If the community is tiny, then you’re getting the worst of both worlds: you don’t get any of the joy or ownership of writing the code yourself, but you do get all the sorrows of understanding someone else’s code and fixing their bugs.
–
[1] Even Spark has a bit of sprawl problem, because its core is in Scala/JVM but the audience of data scientists and analysts are more familiar with SQL and Python. It also has older RDDs and MLLib vs. newer dataframes and SparkML. Still, these features do not change the underlying run-time architecture, unlike Beam’s portability framework. Spark also benefits from being a market leader and its associated network effects.
[2] It was a lot of hard work to understand Flink checkpoints and how they work, how to prevent checkpoint timeouts in Flink, and then finally, to investigate how Beam interacts with Flink and whether Beam provides any way to solve the problem. (It does not, as I mentioned.)